
Design Patterns for Market Data – Part 2: Centralized Ticker Plant
Introduction
*originally posted on LinkedIn*
In Part 2 of our Design Patterns for Market Data series, we turn our focus to centralized ticker plants which remain the dominant architectural response to the scaling limitations of embedded feed handlers.
Ticker plants play a critical role in financial institutions by normalizing and distributing real-time pricing information to a broad range of front office systems: execution management systems, matching engines, order management systems, retail trading platforms, risk management, trade surveillance and compliance monitoring tools.
When implemented well, they consolidate duplicated processing, improve efficiency, and reduce the total infrastructure required to support growing market data volumes.
But like all design patterns, ticker plants come with tradeoffs. While they offer gains in resource efficiency, operational scalability, and cost reduction, they also introduce distribution complexity and latency overhead.
In this article, we explore how centralized ticker plants solve the scale problem, where they shine, and where they introduce new challenges—especially when compared to the embedded software feed handlers examined in Part 1.
Centralized Ticker Plant: Efficiency at Scale
A centralized ticker plant is designed to process each market data feed once and to distribute normalized updates efficiently to downstream trading applications. This reduces redundant processing across multiple servers, conserves compute resources, and simplifies system-wide market data management.
In this design pattern, the ticker plant sits between two networks:
- An exchange-facing network that delivers raw direct feeds from trading venues to the input of the ticker plant.
- A distribution network that transmits the normalized output of the ticker plant to trading applications.
These applications may run on servers co-located in the same data center or located in remote data centers.
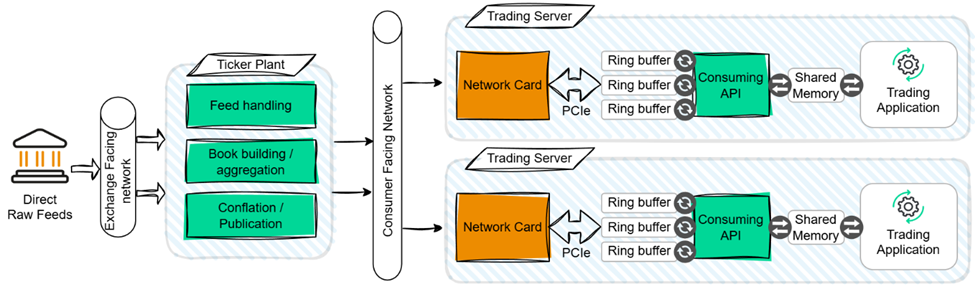
Inside the ticker plant, each incoming feed is processed by a dedicated feed handler that decodes messages and forwards normalized updates to the distribution network for trading application consumption. One of the key architectural decisions is how the ticker plant determines which updates to forward, and to whom. This filtering logic directly impacts both performance and complexity—topics we’ll return to in later section.
To receive market data, trading applications interface with the ticker plant via an Application Programming Interface (API). This API typically allows each application to:
- Request specific financial instruments
- Choose the market data view (e.g. top of book, price-aggregated book, or full depth)
- Select the update mechanism (e.g. trigger on every event or asynchronous snapshot from memory).
The API requires compute resources to process all incremental updates for the requested market data from the ticker plant and to present them to the application in the specified way. While it is important to overprovision processing resources (e.g. threads running on dedicated CPU cores) to keep up with update rates and avoid data loss, API resource consumption is designed to be considerably less than embedded software feed handlers.
Scaling to Handle Bursting Feeds
When implemented in software on commodity servers, the performance and resource analysis from Part 1 of our series applies to the set of feed handlers within the ticker plant. For consistency, we assume that the full set of feed handlers* requires 32 cores to achieve consistent latency performance at a target capacity of 5 million messages per second. Capacity is increased by horizontally scaling—adding feed handler instances and additional processor cores.
The complexity of additional capabilities of a centralized ticker plant can vary significantly. Data distribution to many consumers and aggregating data across multiple markets are primary design considerations. Secondary considerations include user authentication and entitlement enforcement, data loss mitigation and recovery features, data quality monitoring, and operational transparency and control. Depending on the scope of capabilities, a ticker plant implementation may require 50% to 100% more processing cores beyond the requirements of the feed handlers.
For our efficiency analysis below, we assume a ticker plant implemented on two servers (e.g. a total of 128 cores). This provides for input capacity of up to 10 million messages per second which is suitable for processing the protected US equities markets, as well as a robust set of distribution capabilities that require an additional 100% more processing cores.
*Note that feed handler design for a high-capacity ticker plant may use more functional parallelism (i.e. pipelining) to boost the capacity of a single feed handler instance.
Efficiency in Action: A Cost & Core Comparison
For a ticker plant, its efficiency is primarily measured by the relative reduction in market data processing for each trading application. A well-designed ticker plant API is at least twice as efficient processing normalized market data messages relative to an embedded feed handler processing raw market data. In Part 1 of our series, we assumed a well-written software feed handler can consistently process a market data message in 2.5 microseconds, providing a throughput of 400,000 messages per second per processor core. we assume a throughput of 800,000 messages per second per processor core allocated to the API. In practice, higher levels of efficiency can be achieved.
To meet the same design target of 5 million messages per second for the aggregate market data traffic input to our trading system, the API requires 7 processor cores. Over-provisioning resources to provide excess capacity and latency consistency would push the API to consume a total of 10 to 12 processor cores in the trading system.
Using the same assumptions on 32 to 64 core servers and 30,000 USD annual operating cost per server in a colocation datacenter, the total API operating costs are 11,250 USD to 22,500 USD annually*. If the ticker plant can be implemented on two servers**, or an equivalent thereof, the total market data operating costs are 71,250 USD to 82,500 USD annually. This represents a 6x to 11x reduction in annual operating costs per datacenter for market data processing with a centralized ticker plant relative to embedded software feed handlers.
*We assume that our example trading strategy or execution system must consume every market data update once through the API. This holds true even if the workload of the trading strategy is distributed over multiple instances of the application due to the complexity of trading logic, or likewise if the volume of orders to be managed is distributed over multiple instances of the execution system. Each instance is responsible for a subset of the set of financial instruments traded. The ticker plant filters and delivers the required market data to each application instance. Extending the base case to provide multiple copies of market data to downstream consumers reduces the relative efficiency gain.
**Note that most ticker plant deployments include resiliency—multiple ticker plant instances operating in parallel, potentially in different sites, allowing consuming applications to failover and continue operating in the event of a fault. Resiliency design techniques and their implication on operational efficiency are beyond the scope of this article.
Data Distribution Overhead
If the primary design goal is to abstract complexity and offload effort from downstream trading applications, then the centralized ticker plant transmits the required number of copies of each market data update to each application using a unicast (one-to-one) communication protocol. Each client only receives and processes updates for the financial instruments it requests.
This maximizes their efficiency, but it also increases the complexity of the ticker plant design and introduces additional latency overhead for each copy of a market data message that must be transmitted. For well-designed ticker plants, the overhead is dominated by the transmission latency of the normalized market data message. If we assume an average message size of 100 bytes, the transmission latency will be approximately 35 or 142 nanoseconds when using 40Gb/s or 10Gb/s network links, respectively.
This overhead can be negligible when the number of copies is five or less, however an additional microsecond of latency is introduced for every seven copies of a message on a 10Gb/s link. Avoiding the latency overhead of duplication with one-to-one protocols is typically done using a one-to-many protocol, specifically multicast.
Multicast Considerations
Multicast distribution pushes the burdens of data filtering and data correctness* to consuming applications. While the ticker plant operates efficiently by transmitting each normalized market data update only once, the API must filter updates corresponding to financial instruments that the application did not request.
Given the number of variables, quantifying the efficiency degradation due to filtering operations by each consuming application is difficult. A reasonable design target is to ensure that API processing requirements increase by less than 50 percent. From our analysis above, this would increase the API’s processor core consumption from 12 to 18 cores.
*Generally, multicast protocols provided by standard network technology are unreliable. They provide no guarantees for reliably delivering packets in the order they were transmitted. A plethora of solutions have been developed over decades to address this challenge. Selecting a solution is often a matter of technology religion rather than quantitative comparison.
Aggregation Challenges
In addition to data distribution, aggregating prices for fungible financial instruments across multiple markets is another primary capability. When trading applications share interest in a single set of aggregated pricing views it amplifies the efficiency advantages of centralization, as the computational overhead is incurred once. Computing aggregated pricing may consume 50% to 100% more processing resources relative to the feed handlers normalizing the data from each input market data feed.
If there is diversity among applications for the content of aggregated pricing views, central computation can become prohibitively complex. When these requirements emerge, designers often push the aggregation to the consuming applications and therefore increase the amount of processing resources required on the trading servers.
Latency: The Price of Efficiency
The increase in efficiency and corresponding reduction in operating costs is paid for in units of time. The centralized ticker plant design pattern incurs additional latency:
- Data distribution: 1 to 10 microseconds for data distribution protocol processing (e.g. data replication and reliable transmission)
- Network: 100s of nanoseconds (local) to 10s of milliseconds (remote) for data serialization, propagation, and deserialization delays
- API: 1 to 2 microseconds for data filtering, validating, local cache updating, and application notifying
- Optional data aggregation: 1 to 2.5 microseconds for aggregate pricing view updates, either in the ticker plant or API
These latency tolls are additive and make it difficult for centralized ticker plants to reliably deliver normalized market data to trading applications in less than 10 microseconds. This precludes their use for latency-sensitive strategies that target tick-to-trade latencies* under 10 microseconds.
For a broad spectrum of enterprise applications for market data, the centralized ticker plant design pattern delivers sufficient latency performance with favorable efficiency gains.
The Exegy Ticker Plant: Built for Performance and Efficiency
The Exegy Ticker Plant (XTP) is a centralized ticker plant deployed as a fully managed appliance with an easy-to-use API. The XTP includes purpose-built hardware logic in Field Programmable Gate Array (FPGA) devices to achieve superior capacity, speed, and efficiency relative to software running on commodity servers.
For example, a single XTP appliance with the same datacenter footprint as a single server can process the full set of direct market data feeds from all North American equities and commodities markets. This further improves the efficiency analysis above to an 11x to 18x reduction in annual operating costs per datacenter relative to embedded software feed handlers. This level of efficiency is delivered while maintaining impressive latency performance.
Purpose-built hardware logic also enables the XTP to provide flexible aggregated pricing views. Deployment flexibility is maximized by offering a range of options for normalized data distribution.
The Exegy Ticker Plant has served as the trusted market data platform for the world’s leading global banks, brokers, and hedge funds for over a decade. Contact us to discuss your efficiency and performance goals for your next-generation market data platform.


