
Design Patterns for Market Data – Part 1: Embedded Software Feed Handlers
Series Introduction
*Originally posted on LinkedIn*
As real-time market data volumes surge to unprecedented levels, trading system architects are being forced to rethink the core design patterns used to process and distribute data. In this three-part series, Design Patterns for Market Data, we explore the most common patterns in use today, examine the tradeoffs each entail, and offer a quantitative lens for evaluating performance, scalability, and cost. Whether you’re building in-house or evaluating vendor solutions, understanding these patterns is key to designing systems that can scale with tomorrow’s markets.
In Part 1, we examine embedded software feed handlers, a design pattern still widely used in latency-sensitive trading environments. In future installments, we’ll explore centralized ticker plants, followed by a forward-looking vision for systems architectures that eliminates legacy tradeoffs without compromising performance.
Note: This series focuses on systems operating at the millisecond and microsecond scale. Ultra-low latency systems transacting in less than 500 nanoseconds (0.5 microseconds) require specialized architectures, which are beyond the scope of these articles. Contact us if you’d like to learn more about Exegy’s FPGA-based solutions for ultra-low latency trading.
Design Aspirations
As electronic capital markets have matured, common engineering approaches—design patterns—have emerged to tackle recurring problems. Nowhere is this more evident than in the front-office, where systems that transact in real-time depend on high-throughput, low-latency access to market data. Whether you’re building an electronic market-making system or a broker-dealer’s execution algorithm, one need remains constant: access to current pricing and status information (i.e. market data) for the financial instruments that they trade.
At a high level, system designers want a data delivery solution that can:
“Always present the necessary market data to my applications as soon as it’s published, regardless of trading volumes or the number of consuming systems.”
It’s an aspirational goal. No system is infinitely fast or perfectly reliable, and the technology available today requires tradeoffs—among latency, jitter (the variance in speed), processing capacity, breadth and granularity of content, scale of distribution, and overall resiliency. These tradeoffs shape the architecture choices developers must make.
Embedded Software Feed Handlers: Fast and Focused
We begin with the embedded market data processing pattern—commonly referred to as in-process feed handling—which places the software market data feed handler on the same host server as the trading application. That means data is acquired, decoded, and normalized in-process and delivered directly into the memory space used by the trading system.
The figure below provides a simple architectural diagram.
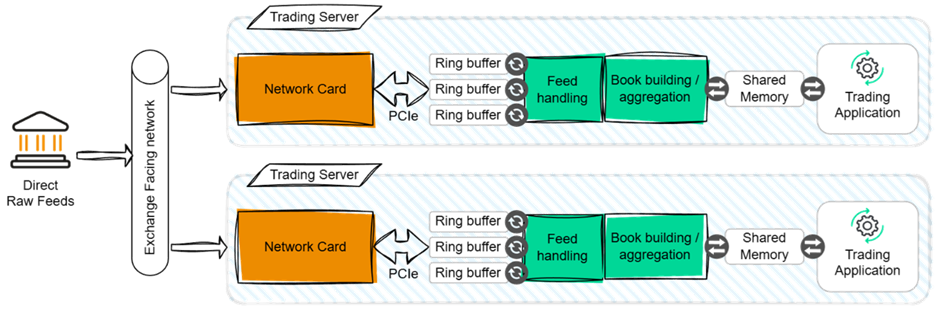
The primary advantage of this architecture is fast data delivery to the trading application. On modern processors, a well-written software feed handler can process and publish a market data message in as little as 2 to 5 microseconds.
Performance will vary depending on the complexity of the protocol employed by the publisher of the market data feed (e.g. the exchange) and the data requirements of the trading application.
⚙️ Performance measurement in the figure above refers to the time between a network packet entering the network card and the placement of the resulting normalized update into shared memory for use by the trading application.
📉 If the trading server is co-located in the same data center as the exchange, then the additional latency introduced is typically less than 3 microseconds — and can be reduced to under 100 nanoseconds with optimized networks and interface cards.
Quantifying Performance: A Practical Example
To illustrate the performance characteristics of this design pattern, let’s assume our feed handler software is well-optimized and consistently processes a market data message in 2.5 microseconds. This translates to a processing capacity of approximately 400,000 messages per second.
High-volume markets like equities traded in the United States can produce market data feed rates that burst well into the millions of messages per second during busy trading periods. In such cases, our single feed handler becomes a bottleneck, leading to poor latency performance as it serially drains a growing queue of unprocessed message
Fortunately, most market data feeds support data-level parallelism: they can be cleanly partitioned and processed in parallel by multiple feed handler instances. This makes horizontal scaling a practical approach for increasing throughput within embedded architectures.
For simplicity, our example uses a single-threaded feed handler that consumes one core. Each additional core allocated scales total throughput linearly—adding another 400,000 messages per second per core. This raises a critical design question:
How many CPU cores should be allocated to market data processing in an embedded architecture?
🛠 Note: In addition to data-level parallelism, software feed handlers may also exploit functional parallelism—dividing processing tasks into pipeline stages, each running on its own core. While this pipelined model often increases the end-to-end latency per message, it can significantly reduce latency variance and increase total throughput, particularly in use cases where data-level parallelism is limited. This approach works best in feed-forward designs that avoid feedback loops.
How Many Cores Do You Need?
Allocating more server cores to market data processing not only increases throughput but also improves the consistency of low-latency delivery to the trading application. However, each core dedicated to feed handling is one fewer available for trading logic or other critical components of the electronic trading platform. While market data workloads often benefit from parallel processing, even high-performance servers have finite compute resources.
A seemingly straightforward approach is to model the system using classical queuing theory. If we assume:
- Market data message arrivals follow a known probability distribution
- Message processing time is constant (e.g., 2.5 microseconds)
- Each feed handler instance is single-threaded
Then we can apply the M/D/1 queuing model to estimate latency performance. This model shows that when the arrival rate is two-thirds of a handler’s maximum throughput, the average queuing delay equals the processing time.
📐 For a feed handler with 400,000 msgs/sec throughput and a 2.5μs processing time: At 266,667 msgs/sec (2/3 load), the average queuing latency is also 2.5μs.
An explanation of this model is beyond the scope of this article, but the key intuition is that average latency begins to rise sharply as server utilization approaches full capacity. Designing to this theoretical latency target implies that a system processing 5 million messages per second would require approximately 19 cores dedicated to running an embedded software feed handler.
In practice, unfortunately, tuning embedded feed handlers is far more complex. Market data traffic rarely conforms to neat statistical distributions, and processing time varies depending on message type, instrument state, and order book depth. Furthermore, low-latency trading systems are not engineered to meet average latency targets—they’re designed to control the tail of the latency distribution, often at the 99.99th percentile.
Returning to our example, meeting stringent tail latency requirements might justify allocating up to 32 cores on a 64-core server—50% of the system’s total compute capacity—just for feed handling. This overprovisioning helps absorb unpredictable message bursts and maintain consistent performance when it matters most.
Strengths of Embedded Feed Handlers
Despite the challenges of tuning and scaling, embedded software feed handlers remain a dominant design pattern in electronic trading systems—particularly for strategies that operate within a single market.
Strategies focused on a limited subset of instruments can operate more efficiently by filtering out unnecessary market data as early as possible. This reduces the volume of messages that need to be processed, which in turn lowers the number of cores required—without compromising latency performance.
Even in environments where a large set of instruments are traded, similar efficiencies can be achieved through striping techniques. By distributing instruments across multiple servers, each server processes only the market data needed for its assigned subset, improving scalability and resource utilization. This model localizes workload and optimizes the use of available compute resources.
Some exchanges support this approach by distributing their instrument universe across separate multicast channels (e.g., via UDP multicast groups). Servers can subscribe only to the channels they need, reducing throughput demands and minimizing latency variance.
Where It Breaks Down
The primary goal of horizontal scaling is to balance workload across multiple feed handler instances—whether on separate cores or distributed across servers. In most systems, market data is striped by symbol or multicast channel, with the allocation configured statically, often based on historical traffic patterns.
However, this static approach is often ill-suited for dynamic market conditions. If the allocation is set daily before the market open, it cannot adapt to sudden spikes in activity—such as news announcements or other market events that cause a dramatic change to the traffic patterns for a given equity and its derivatives contracts.
This can cause a significant workload on the assigned feed handler instance leading to increased latency, higher jitter, or even data loss, all of which increases the risk of trading on stale or incomplete information.
Dynamically reconfiguring the load balancing across feed handler instances introduces significant complexity and can disrupt active trading. As a result, the most common workaround is to over-provision compute resources to ensure sufficient headroom for traffic bursts. But this comes at a cost: designers must weigh the need for performance consistency against the inefficiency of allocating excess capacity.
Embedded market data architectures also struggle in environments where the same market data feed must be processed on multiple trading servers, or where a single server must ingest multiple high-volume feeds. For example, an agency brokerage execution algorithm trading U.S. equities must consume feeds from all protected markets in the National Market System.
Even when instruments are subdivided and striped across servers, market data processing alone can consume 50% or more of total compute resources, leaving less headroom for execution logic and other platform functions. Operating a trading strategy or execution system with this architecture may require 32 to 64 servers. Annual chargebacks by IT departments to business units are approximately 30,000 USD annually per server, primarily driven by space and power costs in co-location datacenters range from 12,000 to 24,000 USD annually per server. This suggests a range of operating costs for embedded software feed handlers of 480,000 USD to 960,000 USD annually per datacenter.
For many trading strategies, these high operating costs may exceed trading returns. Compounding the challenge, additional space is now unavailable in key colocation datacenters, preventing the ability to deploy new infrastructure or horizontally scale existing infrastructure.
Exegy’s SMDS: A Proven Solution
For use cases that align well with embedded architectures, Exegy’s SDMS software feed handlers offer a high-performance, cost-effective solution.
With broad coverage for global markets and an optimized, off-the-shelf implementation, our software feed handlers allow firms to avoid the significant engineering burden of building and maintaining their own market data processing. On average, our clients achieve:
- 8x reduction in development costs (4.1 million USD)
- 2.5x reduction in maintenance costs (3.5 million USD)
- 7x acceleration in time-to-market[dL12] [DT13]
Contact us to learn more about this best-in-class software offering in our industry-leading portfolio of market data solutions that address the full spectrum of performance requirements, as well as our detailed whitepaper that quantifies the value of partnering with Exegy versus developing and maintaining this technology internally.
What’s Next: Centralized Ticker Plants
As market data rates continue to climb, the limitations of horizontally scaling embedded architectures become increasingly unsustainable—not just from a technical standpoint, but also from a business and infrastructure perspective.
This isn’t just a technical scaling issue—it’s a direct business cost that grows without delivering new value. Continuing to allocate more hardware just to maintain current capabilities represents a cost of standing still, not a step forward. The embedded model, while effective in focused deployments, becomes a costly constraint at scale.
In our next article, we’ll explore one of the most common solutions to this challenge: the centralized ticker plant. We’ll examine how this design pattern helps reduce duplication, reclaim compute resources, and efficiently scale capacity—along with the new tradeoffs it introduces around latency and data distribution.


